DeepSeek-V4 來啦!BibiGPT 當天上線 4 款新模型 + 1M 上下文,AI 影音摘要體驗再升級
DeepSeek-V4 來啦!BibiGPT 當天上線 4 款新模型 + 1M 上下文,AI 影音摘要體驗再升級
今天(2026 年 4 月 24 日),DeepSeek-V4 預覽版正式發布並同步開源——百萬 token 上下文成為標配,Agent 能力直追 Sonnet 4.5。BibiGPT 已經第一時間完成接入,DeepSeek V4 Pro、V4 Pro Thinking、V4 Flash、V4 Flash Thinking 四款新模型現在可以直接在模型選擇器裡選用,適合處理一整部紀錄片、一場兩小時的訪談、或者一整季的播客。
我們也在第一時間用幾個真實場景跑了一遍,這篇是同步整理的上手記錄,供有同類使用需求的朋友參考。
目錄
- DeepSeek-V4 這次改了什麼
- BibiGPT 同步上線的四款 DeepSeek V4 模型
- 三步切換到 DeepSeek V4
- 實戰:用 DeepSeek V4 Pro 摘要 DeepSeek 自己的發布影片
- 這幾個場景,切到 V4 會直接生效
- AI 時代,真正稀缺的不是模型,是消費內容的速度
- 常見問題(FAQ)
DeepSeek-V4 這次改了什麼
DeepSeek-V4 一次升級同時動了三個關鍵維度,每一項都值得單獨說。
第一,1M 上下文成為所有官方服務的標配。 新的注意力機制在 token 維度做壓縮,再配上 DSA 稀疏注意力(DeepSeek Sparse Attention),顯存與算力消耗被大幅壓下來。換句話說,投入一小時影片的字幕不再需要「分段再拼接」那套流程,模型可以當成一整段內容一次性理解。
第二,Agent 能力邁上一個台階。 按 DeepSeek 自己的測評,V4-Pro 在 Agentic Coding 上已達到當前開源模型最佳水準,交付品質接近 Opus 4.6 非思考模式,他們內部也已經把它作為預設編碼模型在使用。對普通用戶來說,意味著長文本的結構化處理——分章節、抽要點、生成導圖——穩定度有了明顯提升。
第三,Pro 與 Flash 雙版本互補。 Pro(1.6T 參數 / 49B 激活 / 33T 預訓練)對標頂級閉源模型,Flash(284B / 13B / 32T)更偏重性價比,兩者都支援思考與非思考模式,思考模式還支援 reasoning_effort 調節。簡單任務上 Flash,硬核任務上 Pro,兩邊的使用體驗都相當扎實。

詳細的 blog 原文可以參考 DeepSeek 官方公眾號的這篇:《DeepSeek-V4 預覽版:邁入百萬上下文普惠時代》。模型權重可以在 Hugging Face 的 DeepSeek V4 合集(Pro / Pro-Base / Flash / Flash-Base 四個 repo)下載,技術報告可以直接看 DeepSeek_V4.pdf。
BibiGPT 同步上線的四款 DeepSeek V4 模型
打開任意影片或音訊的摘要設定,在模型選擇器裡搜尋 deepseek,可以看到四個帶 New 標籤的新條目:
| 模型 | 定位 | 思考模式 |
|---|---|---|
| DeepSeek V4 Pro | 頂級效能,高品質結論與長邏輯鏈的首選 | 非思考 |
| DeepSeek V4 Pro Thinking | V4 Pro + 顯式推理,Agent 與深度分析任務首選 | 思考 |
| DeepSeek V4 Flash | 性價比優先,日常短內容 | 非思考 |
| DeepSeek V4 Flash Thinking | Flash + 推理,速度與深度的平衡版本 | 思考 |
怎麼挑? 可以參考這個簡單的決策規則:
- 內容較長(1 小時以上的紀錄片、整季播客、長訪談)→ 選 Pro 或 Pro Thinking,配合深度推理更穩
- 內容較短(30 分鐘以內的會議、日常 Vlog)→ 選 Flash,更快且更經濟
- 希望 AI 分步推理、對比觀點、給出更深分析 → 選 Thinking 版本
- 只需要乾淨的摘要、不需要思考過程 → 選非思考版本
如果不想仔細比較,可以先從 V4 Pro Thinking 開始——它在大多數長內容場景都能給出穩定表現。
三步切換到 DeepSeek V4
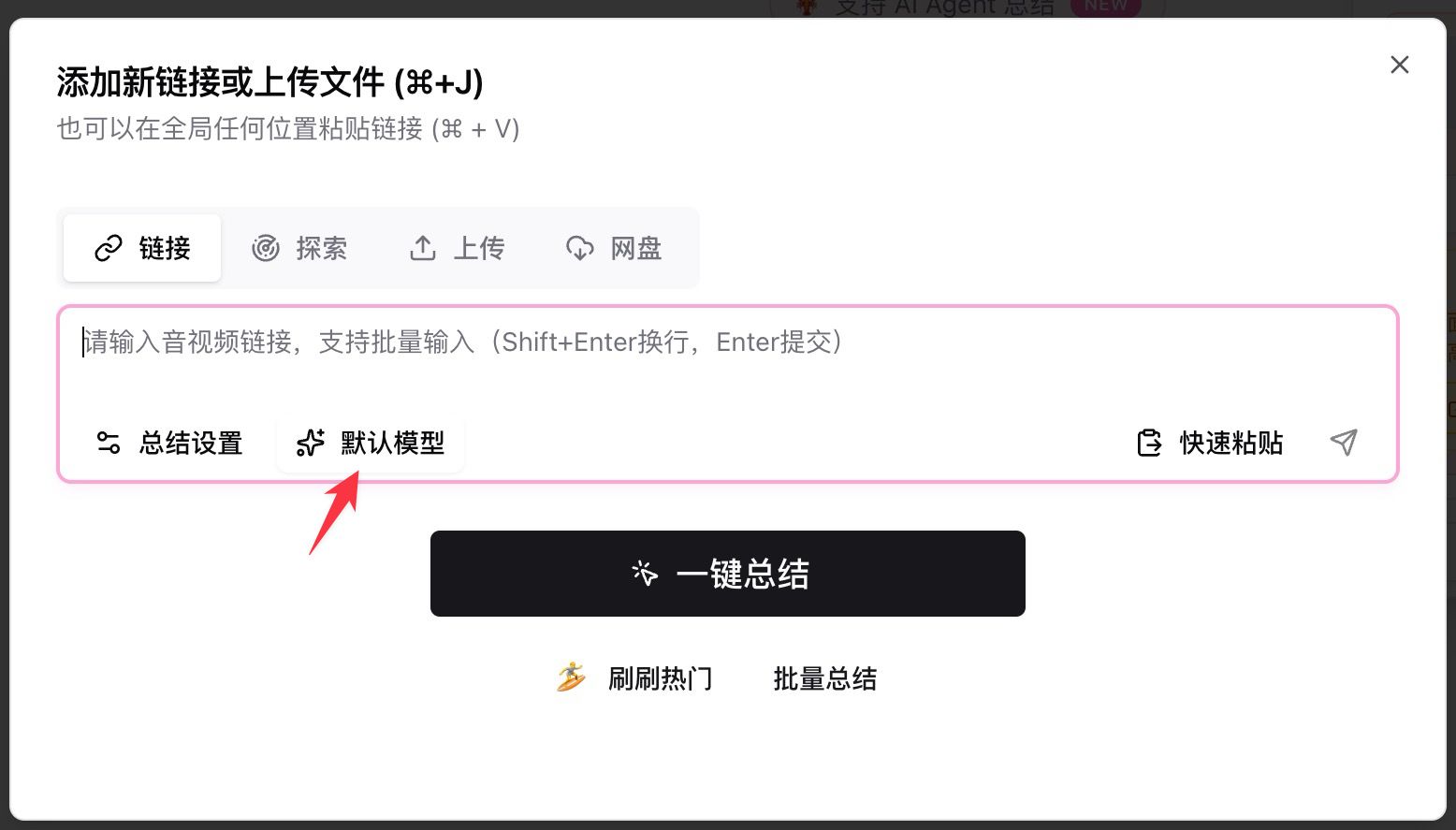
- 打開 BibiGPT,把 YouTube / B 站 / 播客 / 本地檔案的連結貼進輸入框
- 點擊輸入框下方的「預設模型」,在搜尋框裡輸入
deepseek - 從四個 New 條目裡選一款,點擊「一鍵摘要」
選好的模型會在下一次打開時保留。如果你是重度用戶,建議把 V4 Pro Thinking 設為自訂摘要置頂預設,之後任意影片都會走它處理。
想在正式切換模型之前先感受一下 BibiGPT 的摘要效果?在下面的元件裡直接貼一個連結就可以:
實戰:用 DeepSeek V4 Pro 摘要 DeepSeek 自己的發布影片
我們第一件事就是用 V4 Pro 跑了一遍 DeepSeek 自己的發布影片。約一分半的短片,開啟思考模式後,模型把它切成 7 個結構化章節,每一章都帶摘要、亮點、思考與批判性反思。
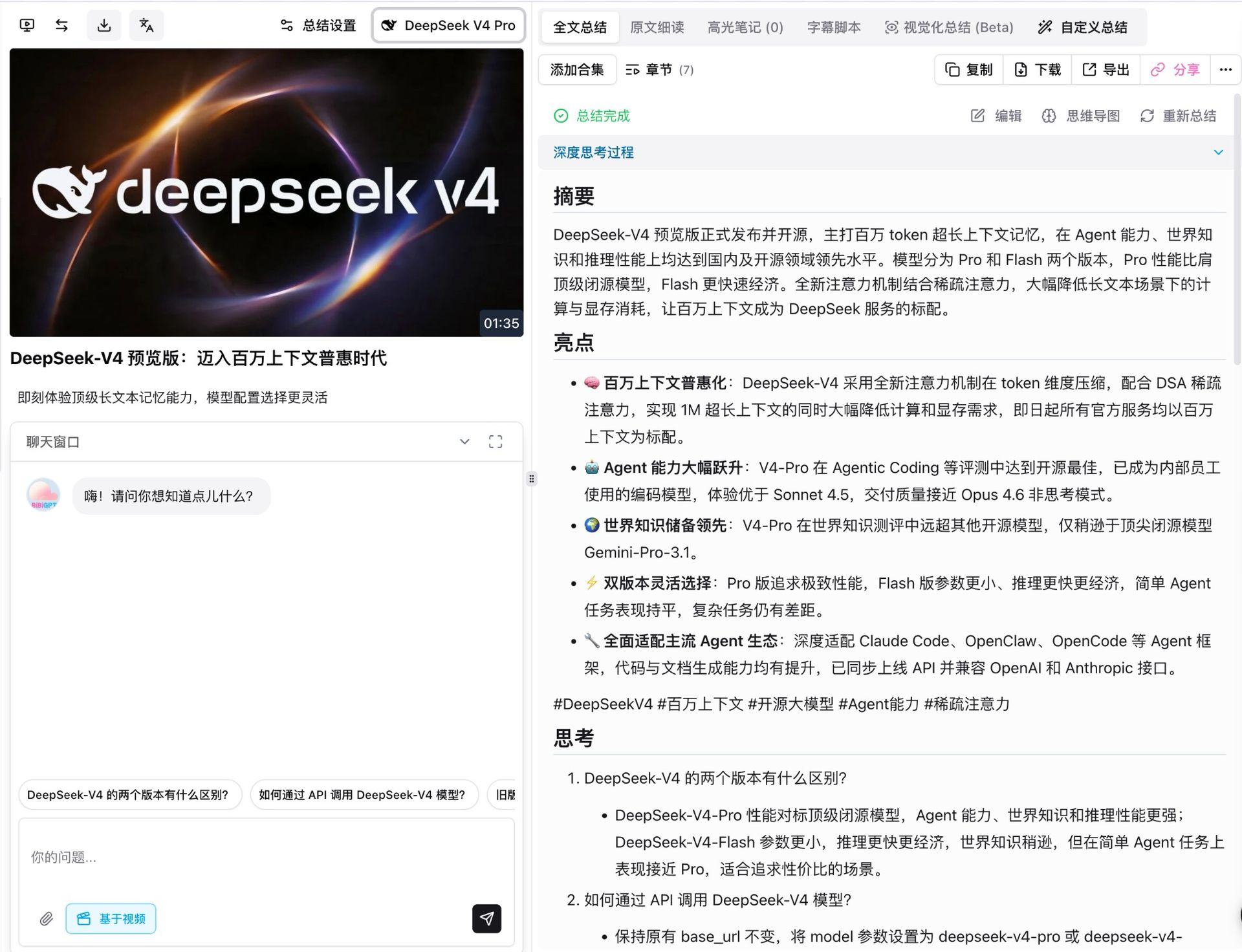
幾個值得提一下的細節:
- 事實覆蓋完整:DeepSeek 發布中的五大亮點(百萬上下文普惠化、Agent 能力躍升、世界知識領先、雙版本靈活、Agent 生態適配)全部準確復現,參數數字也沒有錯亂
- 結論可追溯:每一條結論都掛有可點擊的時間戳,直接跳回影片的對應片段
- 自動延伸:摘要下方會自動產生延伸問題(「兩個 V4 版本有什麼區別?」「如何透過 API 呼叫?」),點開即可繼續深入對話
這裡的提升主要來自 思考模式 帶來的深度推理。BibiGPT 本身在各主流模型上都預設走長上下文路徑,V4 的加入讓開源陣營也能在「深度推理 + 穩定覆蓋全文」這條線上提供第一梯隊的體驗。
這幾個場景,切到 V4 會直接生效
開源模型一家接一家發,有人可能會問:直接在 DeepSeek 官網或者自己接 API 就能用 V4,為什麼還要經過 BibiGPT?
原因在於場景。DeepSeek 官網本身是一個通用聊天框,需要你自己把影片下載、轉錄、貼上、再思考怎麼提問。BibiGPT 做的事情比較純粹:把長影片和播客變得像閱讀文章一樣好消化。V4 是最新加進來的一塊能力,真正讓「貼一個連結就能深度理解一段影音」跑通的,是我們在模型之外已經打磨多年的產品能力。
在 BibiGPT 的現有能力裡,以下幾個場景直接跟隨你在「預設模型」裡選中的模型——換句話說,一旦切到 DeepSeek V4,這些能力就是在用 V4 執行。
📝 影片摘要(預設摘要 + 自訂摘要)
影片貼進來之後最常用的那一下——「一鍵摘要」本身就是用你當前選中的模型生成的。如果你儲存過自訂 Prompt(例如「反常識專家」「批判性思考」「投資分析」等),它們也會走同一個模型。切到 DeepSeek V4 Pro Thinking,同一個影片、同一條 Prompt 再跑一次,就可以直接對比推理鏈和結構化這兩塊的變化——這一塊我們自己也還在持續體驗,歡迎你先跑起來,看看結果是否更貼合你的使用預期。
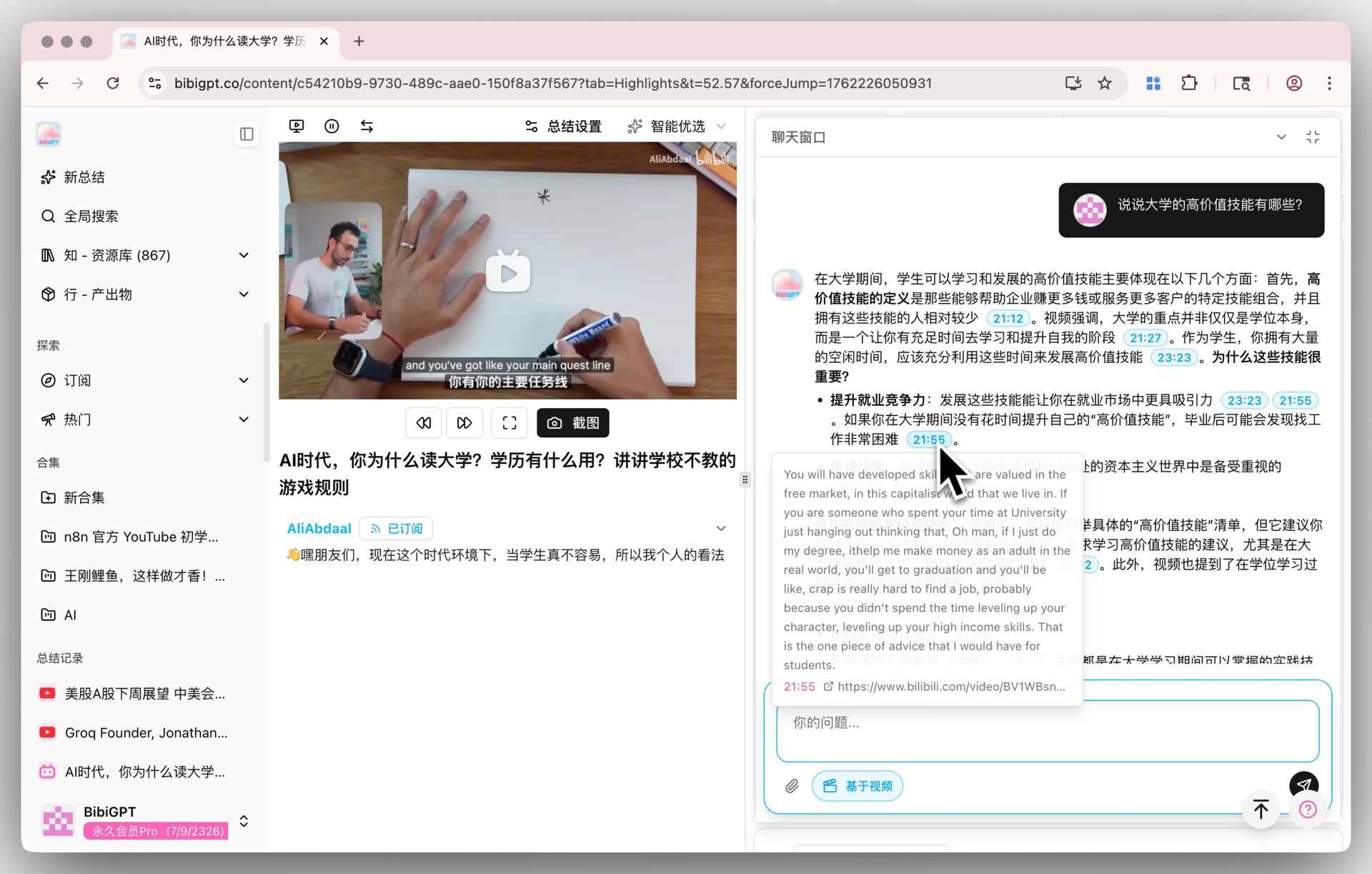
🎯 AI 影片對話與智慧溯源
影片詳情頁下方的「聊天視窗」也跟著預設模型走。每一條答案都附帶可點擊的時間戳——例如「他在 1:12:30 提到過相反的觀點」,一點就能精準跳到那一秒。建議你切到 V4 之後,挑一段 1 小時以上的訪談連著問幾輪追問,這是一個很容易感受到不同模型差異的場景,值得親自跑一次。
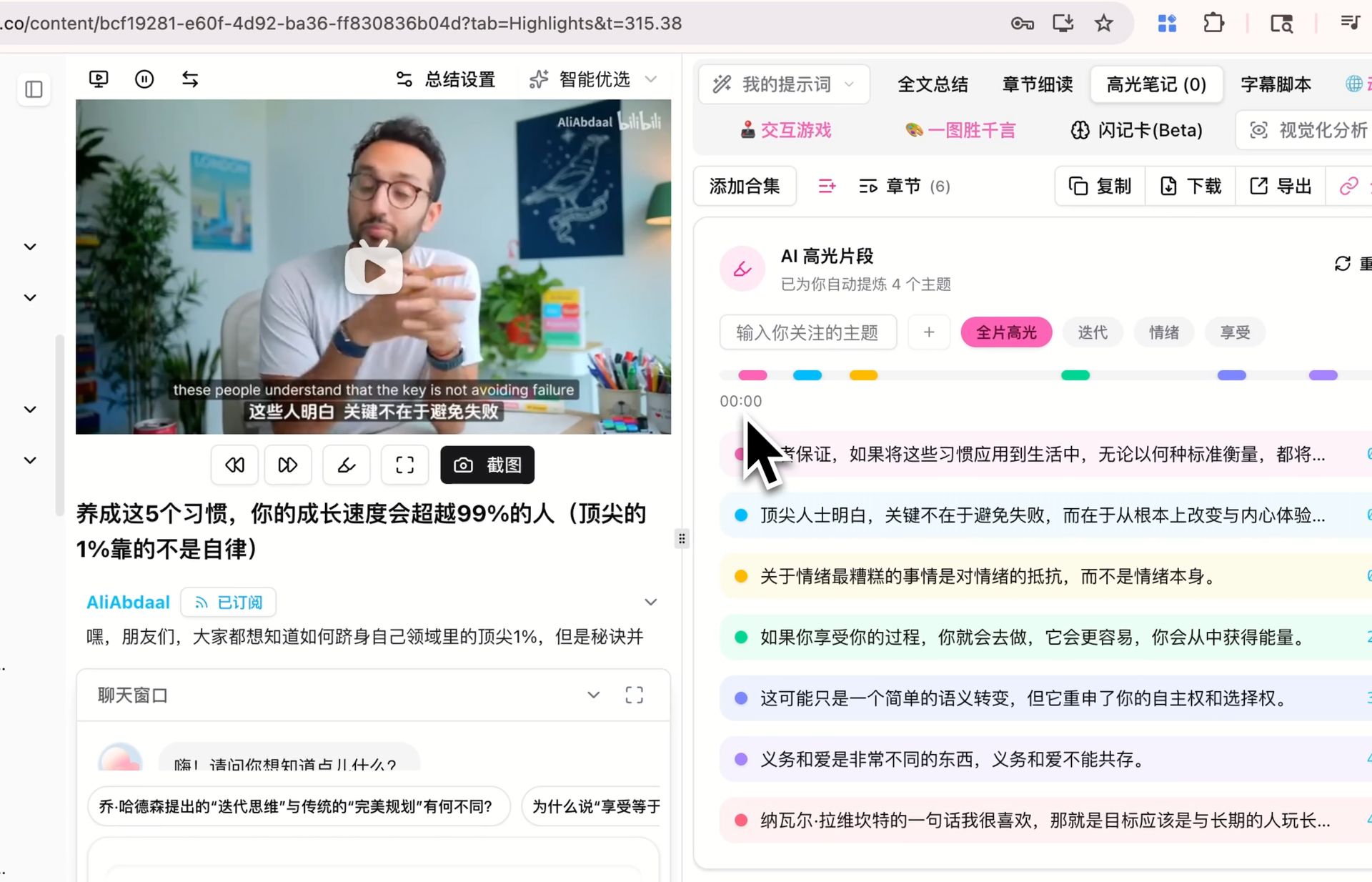
🔖 AI 高光筆記
自動從影片裡挑出帶時間戳的高光片段並按主題聚類,這個過程同樣走預設模型。如果你過去已經用其他模型給某個影片產生過高光筆記,現在切到 V4 再產生一次,對比一下「哪些被挑成高光」「主題是怎麼聚類的」——差異是否明顯、是否更合你口味,直接比一比就清楚。
上面三個場景都是我們目前仍在持續體驗 V4 表現的地方——不同內容、不同 Prompt、不同語言下的效果可能都有差異,結論這事最可靠的辦法還是在你自己的日常工作流裡多跑幾次。
另外,畫面內容分析走的是視覺模型、影片轉圖文文章有固定的管線,這些場景目前不會因預設模型的切換而變化,不在本次的對比範圍內。
BibiGPT 至今已服務 100 萬+ 用戶,累計產生 500 萬+ AI 摘要。這些規模讓我們在接入新模型時能更快地把它對上真實的用戶場景,而不是停留在 benchmark 對比層面。
AI 時代,真正稀缺的不是模型,是消費內容的速度
2026 年的 AI 模型已經像自來水一樣——DeepSeek V4、Gemini 3.1 Pro、Claude Opus 4.6,誰都能調。模型本身不再稀缺。
那什麼變成稀缺了?把資訊消化成觀點、再轉化為行動的速度。
影音是網路上資訊密度最低、消耗時間最長的載體。一場兩小時的訪談,文字轉下來 8000 字,真正值得記住的結論可能只有 300 字;一整季播客 30 小時,長期被引用的觀點也許只有 20 條。過去大家只能 1.5 倍速、2 倍速去扛,用注意力換取密度。大模型能力爆發之後,這筆帳可以重新算了:
- 不必被動聽完,主動提問即可——只問關心的點,模型從字幕中定位答案
- 不必看完再判斷,先讀摘要再決定要不要深入
- 不必一個影片接一個影片地翻,直接跨影片檢索——「訂閱的博主裡誰討論過這個話題」一次搜出來
BibiGPT 做的事情只有一件:把最好的大模型接到「消費影音」這個最大但最難啃的場景裡,讓每個人都能把 2 小時的影片壓成 15 分鐘的高密度閱讀。DeepSeek V4 的加入讓這件事又多了一個可靠的選項。
常見問題(FAQ)
Q1:DeepSeek V4 Pro 和 V4 Pro Thinking 有什麼區別?
核心區別是「是否顯式推理」。非思考模式延遲更低、輸出更短,適合乾淨的摘要;思考模式會先生成一段推理鏈,適合多步邏輯、跨章節對比、論證推演等任務。思考模式還可以透過 reasoning_effort=high/max 調節深度,越深越慢但也越細緻。
Q2:我應該選 V4 Pro 還是 V4 Flash?
可以用「長度 × 推理複雜度」來判斷:1 小時以上、或需要多步推演的內容建議 Pro;30 分鐘以內、只需要乾淨摘要的日常影片 Flash 已經足夠。拿不準時可以先用 Flash,不夠滿意再切到 Pro——BibiGPT 會快取原始字幕,重新摘要不會重複轉錄。
Q3:為什麼要經過 BibiGPT 而不是直接用 DeepSeek 官網?
DeepSeek 官網是通用聊天框,需要你自己完成影片下載 → 語音轉錄 → 貼上 → 提問的全過程。BibiGPT 已經把前置的處理環節(30+ 平台連結解析、轉錄、畫面辨識、時間戳對齊)完成好,DeepSeek V4 只需要負責最後一公里的理解與生成。同一份輸入,你還能額外拿到心智圖、高光筆記、圖文文章、結構化匯出等產物,不需要再自己拼接。
Q4:DeepSeek V4 能處理多長的影片?
V4 Pro 與 Flash 都是 1M token 上下文,中文大約對應 150 萬字,相當於 20 小時的對話內容,或是一整季的長播客。BibiGPT 會根據模型的有效上下文自動決定是做整體摘要還是分段之後再合併。
Q5:DeepSeek V4 的權重開源嗎?
完全開源。權重在 Hugging Face deepseek-ai/deepseek-v4 與 ModelScope,技術報告可以直接打開 DeepSeek_V4.pdf 閱讀。需要自行研究或部署的用戶可以按自己的節奏下載。
現在就體驗 V4
感受 V4 最直接的方式:挑一條你最近本來就想認真看一遍的長影片——一場講座、一期播客、一部紀錄片都行——選上 DeepSeek V4 Pro Thinking 跑一次,看看 V4 在你關心的內容上是什麼手感。
立即造訪 BibiGPT 官網,開啟你的 AI 高效學習之旅:
- 🌐 官網: https://bibigpt.co
- 📱 行動端下載: https://bibigpt.co/app
- 💻 桌面端下載: https://bibigpt.co/download/desktop
- ✨ 了解更多功能: https://bibigpt.co/features
BibiGPT 团队